

The EarthScope-operated data systems of the NSF GAGE and SAGE Facilities are migrating to cloud services. To learn more about this effort and find resources, visit earthscope.org/data/cloud
Imagine yourself on a Saturday morning: birds chirping, Sun rising, cartoons blaring… but one thing is certain, your stomach is growling and you are eager to devour a fresh stack of pancakes.
You open a cookbook:
Pancakes
Serves 5-400.
Ingredients
- Find a field of wheat.
- Harvest a bushel of wheat with a sharp scythe or gassed-up combine.
- Find a cow to milk*, milk the cow, and churn into butter.
- (*) Alternatively, find an orchard of almonds or a field of oats to milk.
- …
Upon reading such a recipe, most people would immediately recoil, as this level of effort and specialization should not be necessary to enjoy the company of friends and family around a meal in the comfort of your own kitchen. Unfortunately, this is what scientific data processing can feel like at times, especially for those that haven’t yet spent years of postgraduate research indulging the intricacies of bespoke data designs that have evolved idiosyncratically over decades. Raw materials are invaluable, but can be difficult to work with. We don’t want to thresh the wheat and churn the butter ourselves.
For example, to process GNSS data in meaningful ways, one must understand the RINEX file format. While the community authors go to great lengths to document this normalized open format that has accomplished so much in geodesy, it is, in a word: unique. It does not look like seismic data, or sea surface temperature data, or weather data, or any other data of any kind that we can think of. Geodesists need an in-depth knowledge of the data format itself before ultimately using the data to pursue their research. There are undoubtedly benefits to the skills acquired in this process, but does upskilling to harvest data embedded in files formatted for punch card readers meaningfully address researchers’ core scientific objective: to turn that data into pancakes?

Enter analysis-ready data
Analysis-ready data minimizes the “toil” of data downloading and preparation. An analysis-ready data archive supports querying “meaningful, complete datasets” that use open source, self-describing storage containers ready for processing. This is what we’re actively striving for as we optimize the NSF GAGE and SAGE data archives for the cloud.
The immediate benefit of analysis-ready data is that it allows researchers to use a familiar set of tools to query (for example) GNSS data arrays within the self-describing schema of time, satellite, and frequency channels without needing to be familiar with the complexities and nuances of RINEX or any other file formats. By leveraging a well-documented and robust API (application programming interface), they don’t need to differentiate between tabs and spaces, L2C or L2P conditions, bit packing and headers, baking soda and baking powder—they can simply query explicitly the time, satellites, and signals they require given the readily apparent shape of the data.
Cloud compute—pancakes for days
Suppose you’re hosting the firehouse breakfast, the breakfast event of the season—and you need to make a LOT of pancakes. We need a way to expand our source of this pancake mix into efficiently scaled-out mixing and flipping of pancakes.
This is big data geophysics—EarthScope seeks to enable these data-intensive workloads like calculating millions of cross-correlations, archive-wide data processing, or machine learning experiments. This analysis-ready data needs to be cloud optimized to efficiently serve scalable compute. Abernathy, et al. describe cloud optimization as a data archive that supports distributed HTTP requests to subsets of data in cloud object stores determined by object-level metadata. In pancake terms, this means arbitrary amounts of batter can be efficiently mixed and poured onto any number of griddles—even if that’s a lot of griddles.
Griddles are a segue into the final piece of this story: cloud compute resources. Compute infrastructure is where the analysis-ready data is made into pancakes. A single API query slicing into this archive can be vastly more intuitive than the raw toil associated with other methods. But the real return on a facility-archive-level investment in refactoring for this approach comes from pairing the efficient parallelism of these analysis-ready, cloud optimized (ARCO) precise data requests with scalability of cloud compute.

In GeoLab, the cloud notebook environment we are developing, we have enabled a cloud compute cluster (Dask Gateway) to distribute the parallelized reads and processing of these object stores using common Python data science libraries. With minimal bespoke coding, we can define the task, list the extent, and point our massively scalable, temporary computer at the problem.
We define how many pancakes of what size and flavor we want, tell it where to get batter and how many griddles we have, and can then quickly be eating the delicious results—without wasted batter. This strategy is generalizable and reusable for science derived from other data sources archived in ARCO formats.
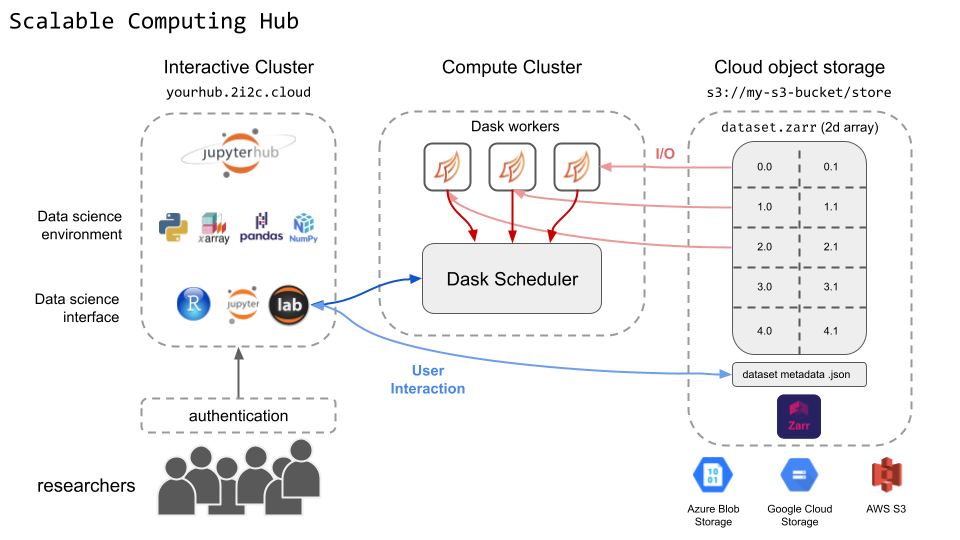
By running code in GeoLab, adjacent to the data in the same cloud, we minimize data transfer between fixed, privileged compute resources. Instead, we seek to leverage scalable, parallelized, high-throughput processing in an equitable cloud environment where only our compressed results are downloaded.
A simple notebook demonstration we ran during the 2024 NSF SAGE/GAGE Community Science Workshop can illustrate how a single intuitive API call to the archive object store can load data directly into a dataframe in memory—no data copied. We can slice into the entire archive to return only data we are interested in and omit any data irrelevant to our research interests.
In our example, we wanted to plot signal-to-noise ratio data over the course of a day for GNSS stations (an arbitrary task, but one that requires running the same compute steps over vast amounts of data). Our first method to achieve this is familiar—downloading daily RINEX files, and calculating signal-to-noise from all the observations in those files. With this method, our notebook in the GeoLab notebook hub took 34 seconds to churn through 9 days of data.
For comparison, an API call to the object store directly pulled signal-to-noise ratio data into a Python dataframe—no downloading and processing of files required. Working this way, our notebook got through 50 days of data in about 32 seconds—a big improvement!
And finally, we aren’t limited to the compute available in the GeoLab instance itself. This same task can be distributed over additional compute via a Dask Gateway with a few extra lines of code. With the help of a cluster of 12 Dask workers, our notebook chugged through 14 months of data in just 27 seconds!
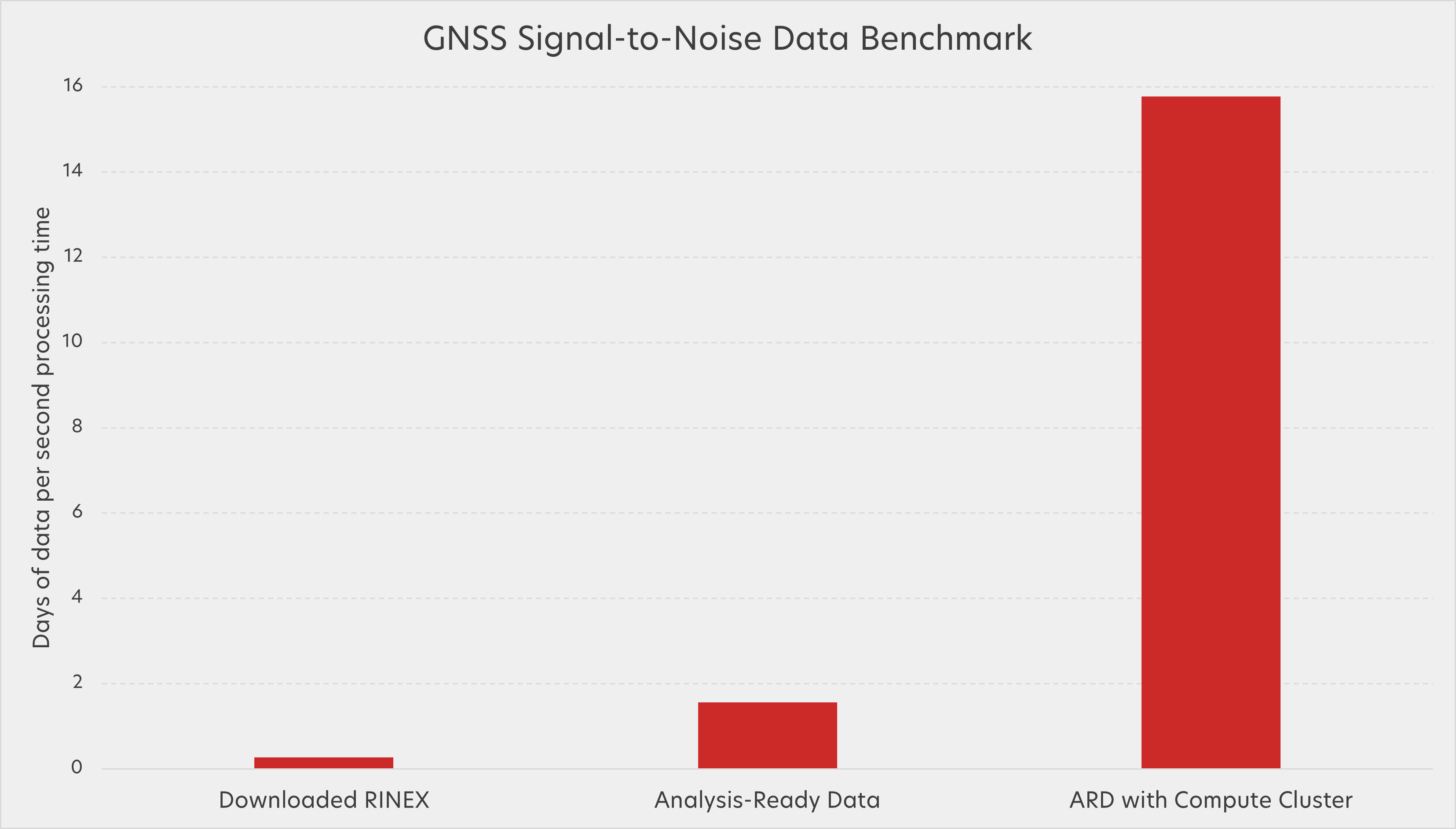
Of course, if you still want to download copies of the daily RINEX files and do all the tedious steps to maintain full control over your grandma’s perfect recipe in GeoLab, you can, but it will no longer be a necessity. Pancake mix is here and it scales quite nicely.
We’ll have more practical how-to information to share on these methods and data object store APIs as we’re able to open up GeoLab to community users and complete the cloud optimization of our data archives. But we hope this helps pique your interest in those developments—and apologize if it made you hungry.