

The EarthScope-operated data systems of the NSF GAGE and SAGE Facilities are migrating to cloud services. To learn more about this effort and find resources, visit earthscope.org/data/cloud
You may find your colleagues’ cloud computing applications intriguing, but figuring out what it would take to make that move with your own work (and whether it would be worth it) can be intimidating. It’s understandably difficult to invest your limited time in a dive into the unknown. If that sounds relatable, a recent paper published in Seismica by Zoe Krauss and colleagues helpfully documents a basic cloud computing project, including a practical introduction to the key concepts you need to know—and the bill they paid at the end.
The data processing task the team needed was earthquake detection in a year of data from an ocean bottom seismometer network. They built catalogs using two methods: template matching on each station’s data (using EQcorrscan) and the application of an existing machine learning model (Seis-Bench) at the network level.
Both methods can be pretty computationally intensive. So after laying out how they would be coded to run on a local computer as a familiar base case, the team explains the steps that were required to adapt it to run on a commercial cloud service—Microsoft Azure, in this case.
Even locally, distributing processing in parallel across multiple CPU cores will greatly reduce runtime, so the team showed how to run your code this way. The cloud computing process is conceptually similar—just with access to cores across as many CPUs as you want—so this approach carries over, with a little modification.
After building out the local workflow, it was time to adapt it for the cloud. Part of it was packaging up the software and data in Docker containers deployable by Azure. The rest was setting up the Azure account and configuring the data analysis job to run.
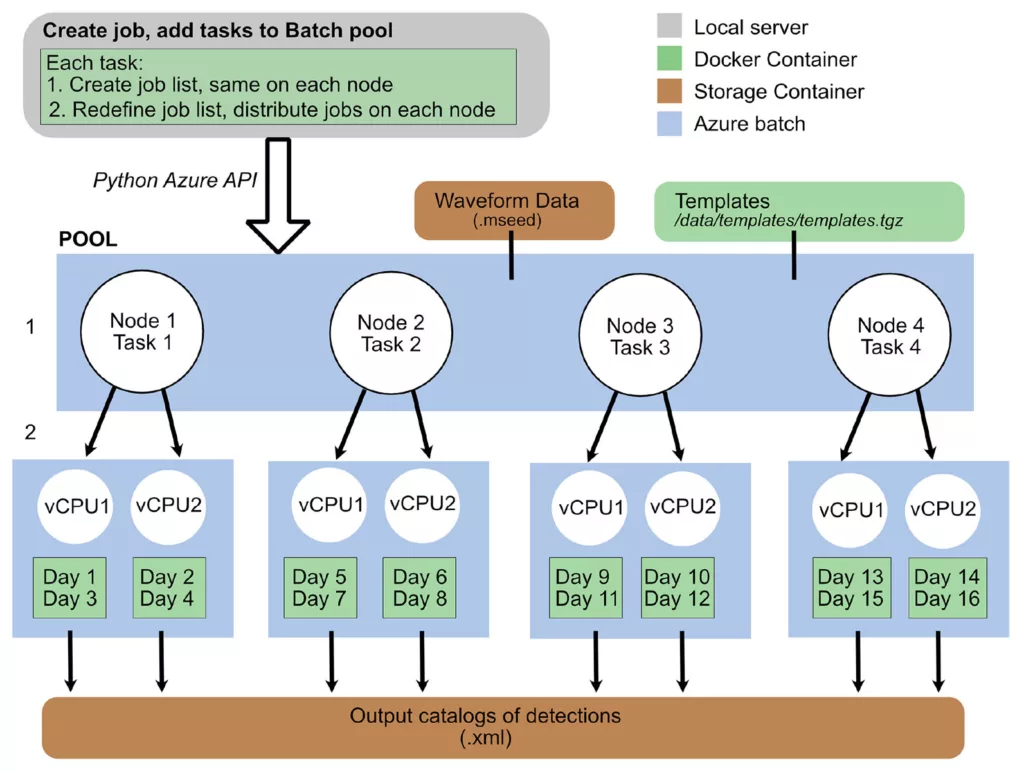
One fact they demonstrated is that since you’re simply paying for minutes of virtual machine use, one virtual machine running for ten minutes costs the same as getting ten virtual machines to complete a job in one minute. Regardless of how many CPUs they split the job across, both earthquake detection methods worked through a year of the network’s data for less than $5.
The team encourages other researchers to consider the value proposition of working this way:
”The learning curve associated with cloud set-up is steep. But, the results of our scaling tests show that seismic processing in the cloud is both cheap and fast. Since the low cost of cloud computing makes large-scale processing more accessible to the seismic community, the migration of local workflows to the cloud is a worthy endeavor.”
That’s particularly true when the alternative would require building or managing larger local computing resources than just your own computer. And as more cloud training materials and support become available, the learning curve is getting a bit less steep.
It’s worth noting that this team downloaded their dataset from the NSF SAGE archive, requiring them to upload the data to Azure and carefully manage storage there to navigate complexity and cost. One of the primary goals of our ongoing migration to cloud data services is that, once they are optimized for cloud storage, you’ll be able to run your analysis in the same cloud system and access the data directly—eliminating the need to move and manage your own copy of a dataset.
You can find the full details of their experience, including code and tutorials, in the paper and an associated GitHub repository. If you’d like to learn a little more, we talked with first author Zoe Krauss about the lessons learned from this project. Please check out that conversation in the video below!